
The generator
Requirements
JRE 1.8 and the full 'resources' folder as it is made available in the 'downloads' page.
Setup
The easiest way to set the generator laboratory is to download the Eclipse Maven project already equipped with all the needed directories, and letting me out of the responsibility to distribute the licensed dependencies
If you met some trouble getting the SprHibRAD artifacts from the Maven Central Repository you can merge the SprHibRAD artifacts tree in your local Maven repository.
The GUI structure
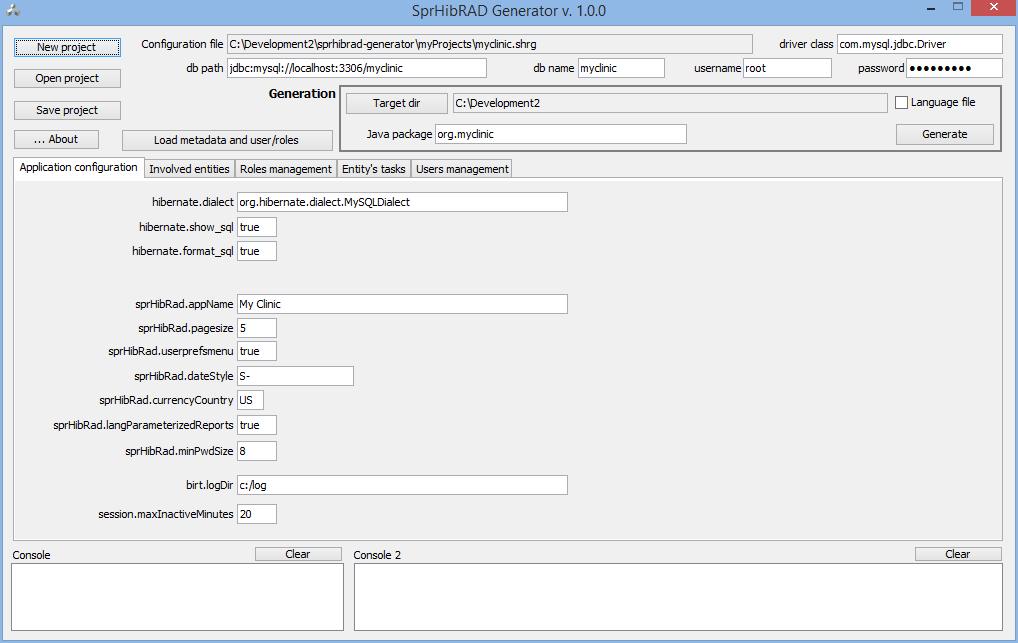
The generator runs as a single-window desktop application that has no classical menu application at the top of the window: the user-actions area is split in two regions, instead.
The upper region contains commands to address/create the generation project, the corresponding data for getting the jdbc connection to the database and the "generation action area".
The lower region is made up by a hierarchal tab-panes structure where each pane identifies a specific context of definition of the generation project. (there are at the very bottom two status boxes - high level messaging is performed on the left and low level on the right).
The 'Application configuration' tab-pane doesn't require explanation for 'sprHibRad'-prefixed properties more than what said about 'Application layout'; the developer of Spring/Hibernate applications certainly knows about the other properties. Below are the descriptions for the other pane.
Notes about the execution flow
At the start-up the generator requires the creation of a new generation project or opens the currently ongoing project (that one referenced at the last saving-operation). The tool doesn't require the connection to the database until it is needed: typically when the 'generate' command is fired or when the user makes a selection that needs database-meta-data to have the system reacting consistently to the selected value in order to enable and/or populate related items.
The loading of the meta-data clear any selection the user could have done. If you are annoyed by that, I advise you to explicitely load the meta-data with the dedicated command at the beginning of your working session with the generator.
Along the whole user interface, when an arrow connects two listbox (directly or through the selection of a 'switching' radio button) the rows of source list-box can be double-clicked to push the row item to the target list-box.
As the user of the generator proceeds in his/her definition, the project tree grows and when saved into the project file, even an indented flavor of the Jason file is saved. The latter is only written: never read. It worth while to remember that the generation project file must not be modified by hand.
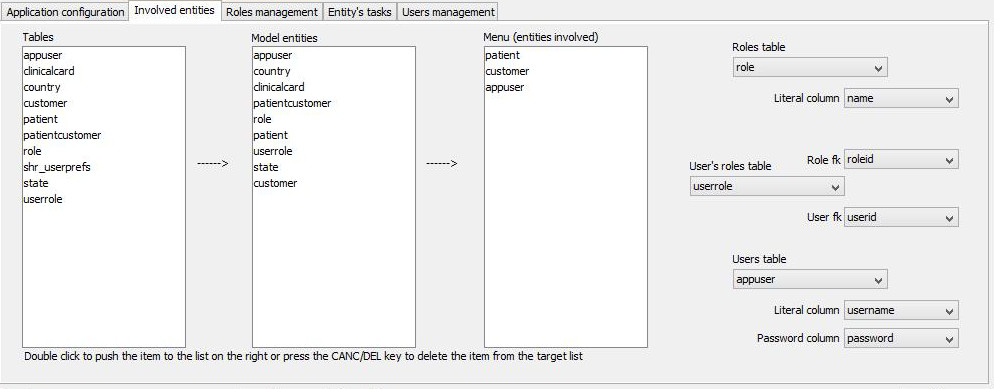
The 'Involved entities' tab-pane
The 'tables' list-box is filled during the loading of the meta-data and is the source of entities that need to be represented in the final application: the adjacent 'Model entities' list-box is the collector of the choices made by a 'pushing' double-click on the rows of the first listbox.
The 'Menu' list-box collects (from the adjacent list on the left) which entities must appear in the application menu (beyond those ones added by the framework: that is, an option between {'user's preferences', 'change password'} and the 'logout' command).
On the right there is a set of drop down lists that identify user and role physical tables in order to let the tool provide the user with users and roles management. These items, even if hosting the selection independently by the meta-data be already loaded in the same session, are not able to display the selected value until the meta-data are loaded.
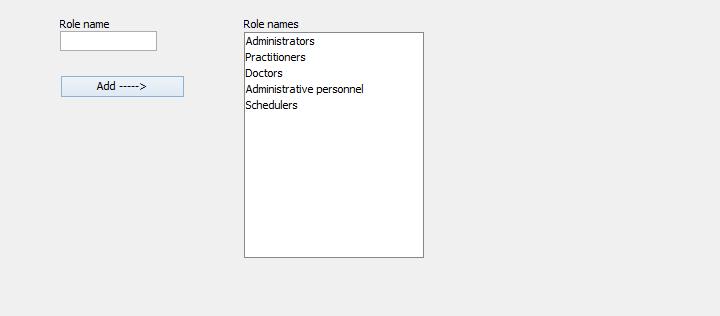
The 'Roles management' tab-pane
Allows to view or to build the list of application roles.
The 'Entity's tasks' tab-pane
It requires the user to select the entity of interest among those ones 'involved' in the project, it
defines how each entity is processed by the final application or, in other words, when and how the entity appears along the application execution and it is made up by a set of pane, all referring to the entity selection made at the top of its area.
Its sub-panes and respectively contained items are:
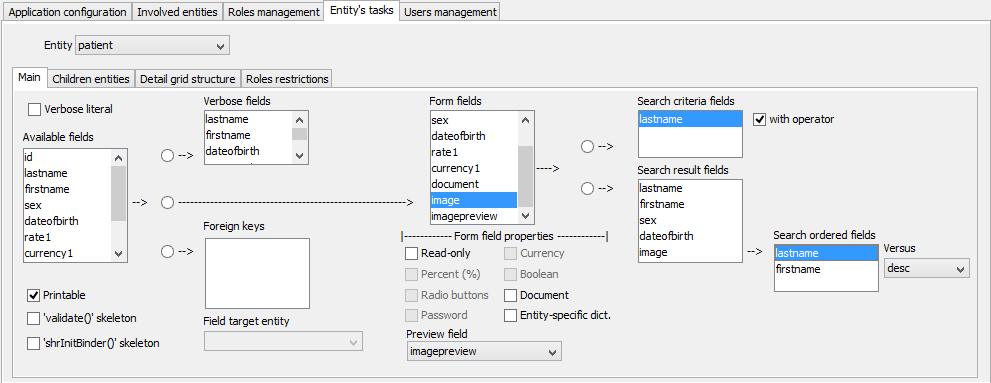
- Main
- Verbose literal states whether the entity is a list of literals representing values domain for some other entity's attribute. Any attribute that will be defined having this entity as 'Field target entity' (see below), will be rendered in the final application as a drop-down list.
- Printable if checked the generator will add a print button in the buttons at the bottom of the page when the entity is recalled by the user through the search/list page. The button is then bound to the launch of the Birt report define by the file named "[entity-name]List.rptdesign".
- 'Validate()' skeleton and 'shrInitBinder()' skeleton drive the generator to insert two methods in the @Controller annotated class (associated to the entity) that prepare further integration with Spring MVC.
- Available fields fills only after a 'load meta-data' event and lists the physical fields detected by the jdbc connection for the entity's table, and that can participate in the definition of various aspects in the rest of the pane.
- Verbose fields specifies how the final application will name a specific instance of the entity: which fields to be used in a blank-spaces catenation.
- Foreign keys indicates which fields are to be considered that way.
- Field target entity indicates the entity that is target of the currently (just above) selected 'Foreign key' field.
- Form fields are the attributes that will appear in the final application when an entity instance is inspected through the data-form page.
-
Form fields properties all refer to the currently (just above) selected field and are respectively :
- Read-only : the attribute will be only viewable
- Percent (%) : the attribute will be rendered as percent value when viewed and as a decimal number when edited
- Radio buttons : states that the attribute value will be managed though a set of radios buttons. The generator's (and more in general the entire suite) offers this kind of user interface expression only for integer numbers and ignores the domain range of the attribute, so that the generator will insert a fixed sized set of fictitiously labeled buttons; the developer will need to complete the job with the exact size of the set and semantic labeling.
- Password : the field is managed a password.
- Preview field : states that the currently selected form field has the value indicated by this drop-down list as binary container hosting a preview of the image stored in the form field itself.
- Currency : the field is managed a currency.
- Boolean : is represented with a check-box
- Document : is a binary container that doesn't need a preview field and is rendered only when explicitely recall by the user that has clicked on the dedicated link-icon.
- Entity-specific dict. : says that the form field has in the dictionary file a dedicated placeholder identified by a key prefixed with the entity name: the language translation is entity specific - by default all the attributes having the same name have the same translation.
-
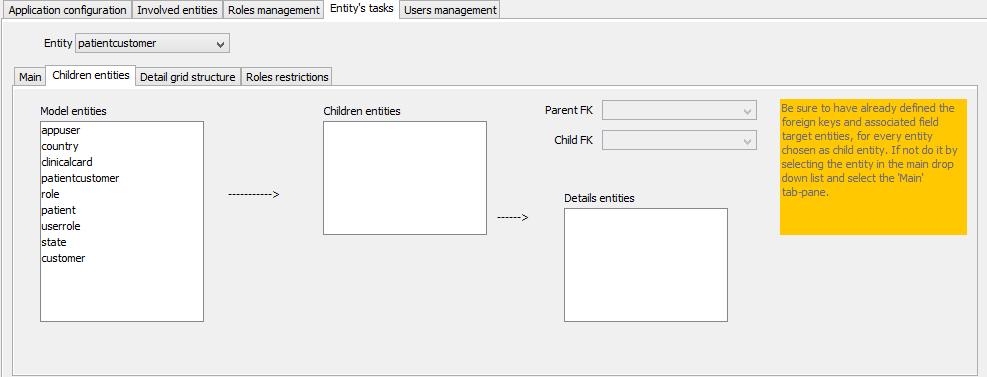
Children entities
This pane defines which other entities are directly related to the currently selected entity for the purpose to present, within the data form page, one or more details data grids related to the entity's main data (that's why the 'children' word was used).
It is fundamental to respect what suggested in the orange memo in order to have 'Parent FK' and 'Child FK' properly populated.
By populating the 'Children entities' list-box also the 'Details entities' is filled by the same name: that is the default scenario - a one-to-many relation where the 'details' content matches the entity that is directly related with the main entity.
The 'Parent FK' is required and simply indicates which field, in the related entity, 'points' to the main entity
In the case the child entity is not what is to be exposed as details because it is a relation entity (that is it sustains a many-to-many 'link') between the main entity and the actual entity the content of which is to be exposed, well also the 'Child FK' must be specified (this one indicated 'the other side' of the relation).
-
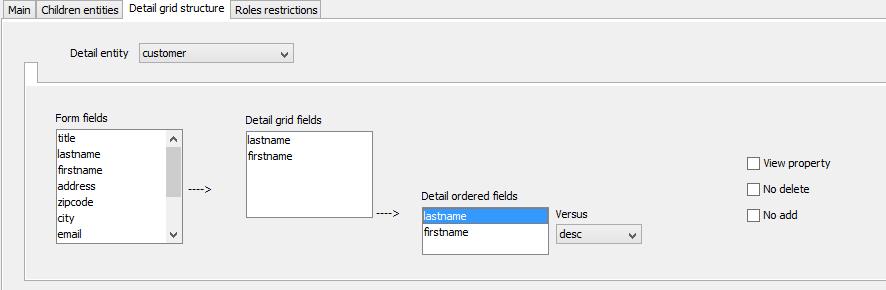
Detail grid structure
It requires the user to select the 'detail entity' from those ones available for the currently selected (top selection) entity.
So the available fields needs to be 'pumped' to the various list-box to define the structure of the details data grid, but which is the available fields ? It was reasonably assumed that any field that needs to be shown in a data-grid, for a certain entity, must at least be represented in the data-form dedicated to the same entity; so that the available fields are the form fields for the same entity.
Then the 'Detail ordered fields' are those of the grid that participate in the default ordering schema.
'View property' must be set when the details entity is not directly related with the main entity (that is, there is a relation entity in the middle, and the final data-grid is desired to have the 'view' row command to lead to the actual detail record and not to the relation entity record.
'No delete' avoids the presence of the row 'delete' command and 'no add' avoids the presence of the upper 'add' command-link.
-
Roles restrictions
'Available roles' is filled after a 'load meta-data' event.
'Available access modes' content is strictly bound to the SprHibRAD framework: for each entity it is possible to specify that one role is needed by the user to make some access type.
For each role pumped in the upper list-box, by selecting the value, it is possible to specify one or more access mode that will enable that role to access the above selected entity.
What here defined is converted in Spring Security clauses in the final application.
The 'Users management' tab-pane
It is an helper feature since a connection to the target database is available and, even, the dedicated tables to users and roles representation are mapped by the generator tool. As clearly highlighted, however the underlying ddl for the dbms level definition of user is provided only for MySql.
In the lower area the attribution of roles to each user is made possible.
The user management is available in the generated web application, too.
The generation
When all the things are set, the developer can fill the boxes within the 'Generation' frame and click (remember the requirements) on the 'Generate' button. It is important, the first time, to set the 'Language file' check-box, else no application-dependent dictionary skeleton is generated.
A full Dynamic web application will be generated, ready to be opened as a Maven-based Eclipse (Oxygen) project.
Note: SprHibRAD generator doesn't create the report design files ('[entityName]List.rptdesign' files) expected by the framework in the 'WebContent/reports' directory when, for some entity, the 'Entity tasks'->'Main'->'Printable' was set): they must be created by hand by using the proper Eclipse flavor built for reporting tools.
If BIRT is needed, the BIRT engine jars must be located in the lib folder of the servlet container or in the 'WebContent/WEB-INF/lib' folder of the web project.
In the 'src/main/resources' path of the project a SprHibRAD dictionary file (messages_en_US.properties) and an application specific dictionary file (dictionary_en_US.properties) are the only language provided by the generator.
The dictionary_en_US.properties file needs to be completed by hand in the right part of each row for the application to run in an understandable flavor. The prefix present in each key should be sufficient to the developer to be able either to recall the semantics or to understand the context in which the keyed literal is used along the application structure.
If other languages are desired, it is enough to duplicate the pair of dictionary files making the needed translation in the new pair (a derivation for each adding language is to be done, obviously). The user of the generated application will find all the languages provided in the user's preferences context (when it is available due to a convenient configuration settings - see, for that, the application.properties file in the resources folder of the generated project).
----------------------------------------------------------